


Scrape, Convert & Read on Kindle
Convert web documentation to EPUB with PyWebDoc2Ebook.


Why I created PyWebDoc2Ebook?
I enjoy reading tech documentation every day. I am also a big fan of the Kindle e-reader, simply because it helps me to read for hours without eyestrain.
I've been reading a lot of the AWS documentation to study its wide range of services. Some of the documentation is available for Kindle, but the majority is not. That is why I created PyWebDoc2Ebook. It scrapes AWS documentation for a given service and converts it to an EPUB file. I can send that file to my Kindle device and read it offline.
The first version was hard-coded to work with AWS documentation. Then, I refactored it to support any documentation on the web via a plugin system.
Using PyWebDoc2Ebook
Very simply, you can execute the following script with the documentation URL.
$ python3 epub.py \
https://docs.aws.amazon.com/vpc/latest/userguide/what-is-amazon-vpc.html
How does it work?
At a high level, the Python script will take the following steps.
Gets the table of contents.
Downloads the HTML content.
Converts the HTML to Markdown.
Improves the Markdown formatting.
Parses and downloads all the images.
Converts the Markdown file to EPUB.
Each step in detail
Step 1. Gets the table of contents
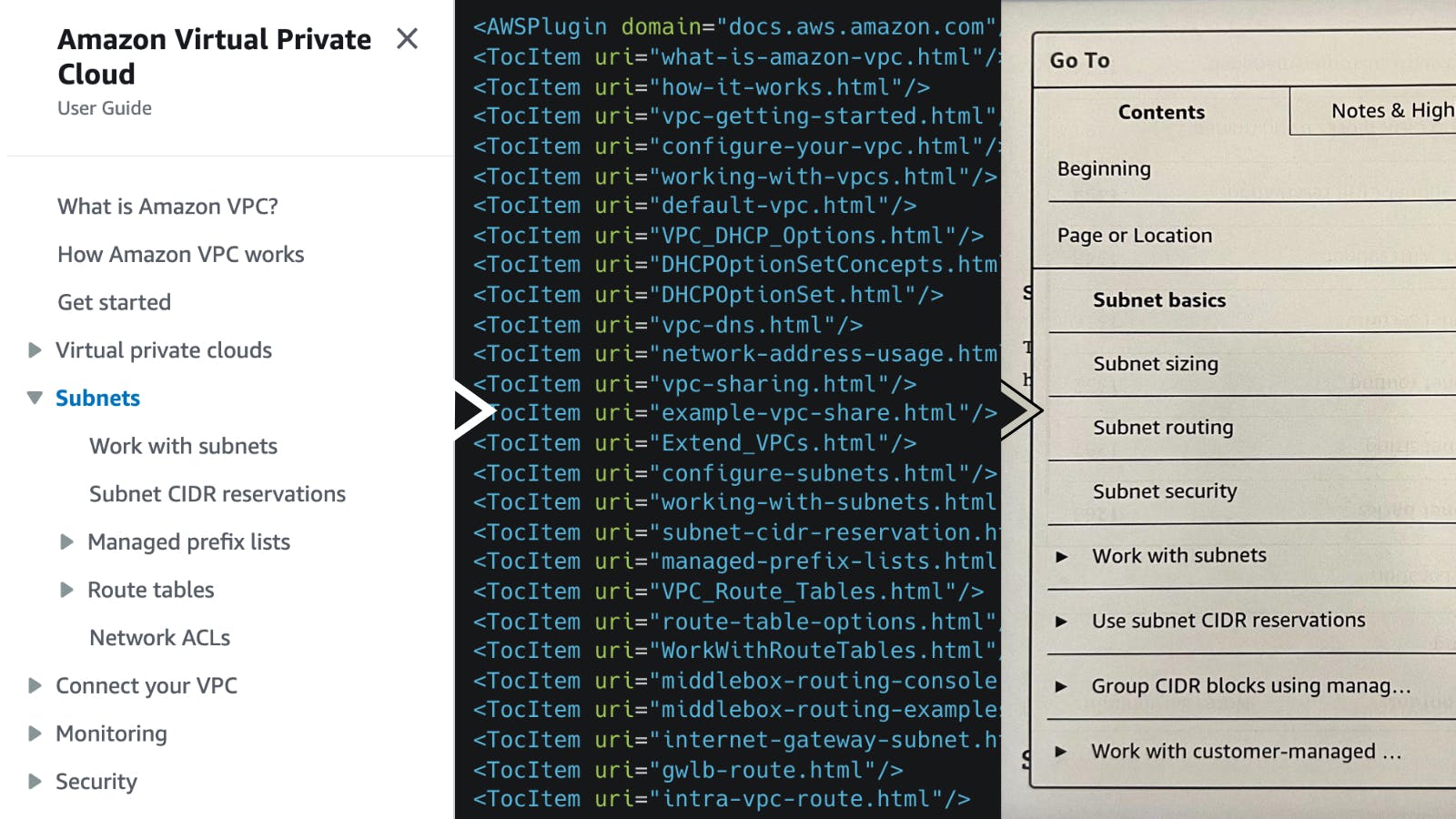
The script is capable of parsing the table of contents from the initial HTML response or loading a TOC JSON file. In the case of AWS, a toc-contents.json file is available for the documentation of each service. You can see an example here.
Let's take the Amazon Virtual Private Cloud documentation as an example. The following image shows three steps in the conversion of the table of contents. On the left is the original table of contents from the web documentation. The middle shows the console output when running the script. On the right is the resulting table of contents on the Kindle e-reader.
Step 2. Downloads the HTML content
You will see the console output when you run the script. For each TocItem , the URI is resolved to an absolute URL and the HTML is downloaded.
<AWSPlugin domain="docs.aws.amazon.com"/>
<TocItem uri="what-is-amazon-vpc.html"/>
<TocItem uri="how-it-works.html"/>
<TocItem uri="vpc-getting-started.html"/>
<TocItem uri="configure-your-vpc.html"/>
<TocItem uri="working-with-vpcs.html"/>
<TocItem uri="default-vpc.html"/>
Step 3. Converts the HTML to Markdown
The downloaded HTML is converted to Markdown and appended to a single file.
markdown = markdownify(html, heading_style=markdownify.ATX)
Step 4. Improves the Markdown formatting
The script cleans up the markdown content and removes excess whitespace. By defining a markdown() function within a plugin, you can hook into the markdown pre-processing and perform additional modifications before it is converted to EPUB.
def markdown(self, md) -> str:
# Modify the markdown content before it is converted to EPUB.
return md
Step 5. Parses and downloads all the images
The documentation often has diagrams, concepts and code samples that are included in the conversion. The script automatically parses all images from the content and downloads them to the resources/ directory. Those image files are included in the final packaging of the EPUB file. These images can be viewed on the e-reader, the same as in the original web documentation.
Processing image: egress-only-igw.png
Processing image: connectivity-overview.png
Processing image: dhcp-custom-update-new.png
Processing image: inter-subnet-appliance-routing.png
Processing image: subnet-diagram.png
Processing image: vpc-migrate-ipv6_updated.png
Processing image: default-vpc.png
Processing image: dns-settings.png
Step 6. Converts the Markdown file to EPUB
The conversion from Markdown to EPUB was made simple with the Pandoc conversion tool. The script is run automatically at the end of the conversion process.
pandoc --resource-path ./resources --metadata \
title="What is Amazon VPC" \
author="docs.aws.amazon.com" \
language="en-us" \
-o amazon-vpc.epub amazon-vpc.md
Plugin System
Within a plugin, you can define the patterns of the documentation that you want to scrape and convert. You can drop a custom python plugin into the plugins/ directory and define a custom class that extends the base Plugin class.
Example: AWSPlugin
In the code below, you can see some of the most essential properties.
domain - activates the plugin when a matching URL is requested.
html_content_selector - the DOM tag where the page content is found. This helps ignore the other page sections like navigation, sidebar and footer.
toc_filename (optional) - By default, the table of contents is parsed from the original HTML response. This option allows specifying a filename that explicitly contains the TOC data.
toc_format -
htmlorjson. Defaults tohtml.toc(response) - you can add one of two functions:
toc_html()ortoc_json()to define how the table of contents should be parsed and registered.toc_html(soup: BeautifulSoup) - takes an instance of BeautifulSoup as an argument representing the table of contents from the HTML response.
toc_json(json: dict) - takes a dictionary object representing the table of contents from the JSON response.
In the AWSPlugin the TOC is a JSON file with nested items. In this case, the toc_json() function searches recursively for child items and registers them in a flattened array ofTocItem.
from Plugin import Plugin
class AWSPlugin(Plugin):
domain = 'docs.aws.amazon.com'
html_content_selector = '#main-col-body'
toc_filename = 'toc-contents.json'
toc_format = 'json'
def toc_json(self, json):
if 'title' in json and 'href' in json:
self.add(json['title'], json['href'])
if 'contents' not in json:
return self.items()
for child in json['contents']:
self.toc(child)
return self.items()
Included Plugins
AWSPlugin | docs.aws.amazon.com | stable
AzurePlugin | learn.microsoft.com | experimental
GCPPlugin | cloud.google.com | experimental
The challenges of web scraping
There are many know challenges with web scraping. In the context of developing this script, the challenges were:
Some sites lazy load their table of contents with JavaScript. I've considered crawling the content with the Selenium Crawler. I may implement this in the next version of this script. For now, it was simpler to work with the available JSON table of contents.
Different TOC HTML and JSON structures. It was challenging to develop a plugin system that would allow customized parsing in the simplest way possible.
Extracting the relevant links and asset URLs with RegEx. The challenge has been striking a balance between standardizing the plugin interface and its precision. To remedy this, I added the ability to customize the RegEx for links.
The challenges of developing the script
Malformatted content resulting from the conversion from HTML to Markdown. These were corrected via RegEx replacements and the hooks in the plugin system allow for further customized corrections.
Nailing the plugin system was the biggest challenge and required a few days of refactoring and testing out different documentation sites and structures. There is still a lot of room for improvement.
Thanks to great open-source packages
I developed this script by combining these awesome packages. It would not have been possible without them.
BeautifulSoup - https://pypi.org/project/beautifulsoup4/
Used to extract the table of content links and to remove unnecessary content sections with DOM selectors.Markdownify - https://github.com/matthewwithanm/python-markdownify
Used to convert all downloaded HTML into a single Markdown file.Pandoc - https://pandoc.org/
Used to convert the Markdown file to an EPUB file and generate the EPUB table of contents based on the Markdown headings.Ebook Convert by Calibre - https://manual.calibre-ebook.com/generated/en/ebook-convert.html
Used to convert the EPUB file to other formats like MOBI.
Development Status
The most stable plugin is the AWSPlugin. The rest of the plugins are experimental and the overall plugin system might evolve. Eventually, I plan to turn this into a proper Python package and publish it. For now, you can fork or clone it from GitHub and take it for a spin. You are welcome to send issues and pull requests there.
You can find it here.
https://github.com/brignoni/py-webdoc-2-ebook
Final Thoughts
I enjoy developing useful automation tools. For me, this was a great exercise for practicing Python object-oriented programming, designing plugin systems and using various parsing and conversion tools. These are patterns I can reuse in other projects. Overall, it was a very fun experience.